Qu’est ce que le Retrieval Augmented Generation (RAG) et comment construire une application RAG avec n8n et Supabase.
Premiers pas avec le Retrieval Augmented Generation (RAG)¶
Si vous vous intéressez un peu aux actualités autour de l’IA, vous avez certainement entendu parler des GPTs, la dernière fonctionnalité de ChatGPT. Il est possible en quelques clics d’uploader des documents pour construire un chatbot personnalisé. Sur le papier ça semble parfait, mais en pratique j’ai constaté plusieurs limitations.
Je me suis donc intéressé au développement d’applications IA en propre (sans passer par ChatGPT) et j’approfondis le sujet depuis quelques semaines. J’ai beaucoup appris, beaucoup testé. Les informations en français sont tellement rares que j’ai décidé de partager mes recherches ici pour vous proposer le contenu que j’aurais aimé trouver. Dans ce billet, je vous expliquerai
- pourquoi les GPTs ont vite été limitants dans mon cas
- que sont les embeddings
- qu’est que le RAG comment on peut construire une application IA
- mes premiers retours d’expérience.
Les GPTs et leurs limites¶
Les GPTs (le “s” a son importance pour différencier du produit d’origine ChatGPT) désignent une fonctionnalité de ChatGPT qui permet de créer en quelques clics des chatbots personnalisés grâce à une interface où l’utilisateur peut importer des fichiers et configurer le prompt initial. Ces chatbots sont capables de rechercher dans les fichiers fournis pour trouver des éléments pertinents et générer des réponses.
Quand j’ai voulu utiliser cette fonctionnalité sur des cas clients concrets, j’ai constaté deux limitations majeures :
- on ne peut fournir que dix fichiers au maximum (on peut contourner la limite en fusionnant ses documents en un seul fichier texte, mais ce n’est pas vraiment satisfaisant).
- c’est une boîte noire. Impossible de modifier des paramètres techniques tels que la température du modèle. On ne sait pas non plus comment fonctionne la recherche d’information dans les documents et on ne peut donc pas paramétrer ce processus pour l’adapter à un contexte particulier.
Dans mes essais sur des cas exigeants, les résultats étaient souvent décevants et inconstant.
Je vous recommande néanmoins de tester les GPTs qui sont très utiles pour développer rapidement des chatbot simples. En outre, les GPTs offrent d’autres fonctionnalités inédites comme la possibilité d’appeler des services externes (API) ou d’utiliser un “code interpreter” ce qui ouvre énormément de perspectives.
Context window¶
Trop limité dont par les possibilités offertes par les GPTs, j’ai donc voulu savoir comment développer un chatbot capable de rechercher des informations dans une base de connaissances volumineuse (plusieurs centaines de fiches techniques au format PDF).
Pour cela, il est nécessaire de comprendre certaines contraintes techniques propres aux modèles de langages (LLM), notamment la context window. Cette fenêtre représente la limite d’information que le modèle peut traiter en entrée. Cette limite est exprimée en tokens qui sont une unité de découpage du texte (pour simplifier, on peut considérer l’approximation 1 token = 1 mot, même si la réalité est quelque peu différente).
Il est donc important de prendre en compte la context window lorsque l’on utilise les modèles de langages :
- il faut que la quantité d’information que l’on fourni au modèle puisse rentrer dans la context window
- plus la quantité d’information donnée en entrée est importante et plus la réponse sera lente à coûteuse (et oui la facturation est directement proportionnelle au nombre de tokens)
Impossible donc de fournir tous les documents de votre entreprise à une IA pour lui demander une réponse à une question précise. Il faut ajouter une étape pour qui consiste à extraire seulement la partie utile de l’information.
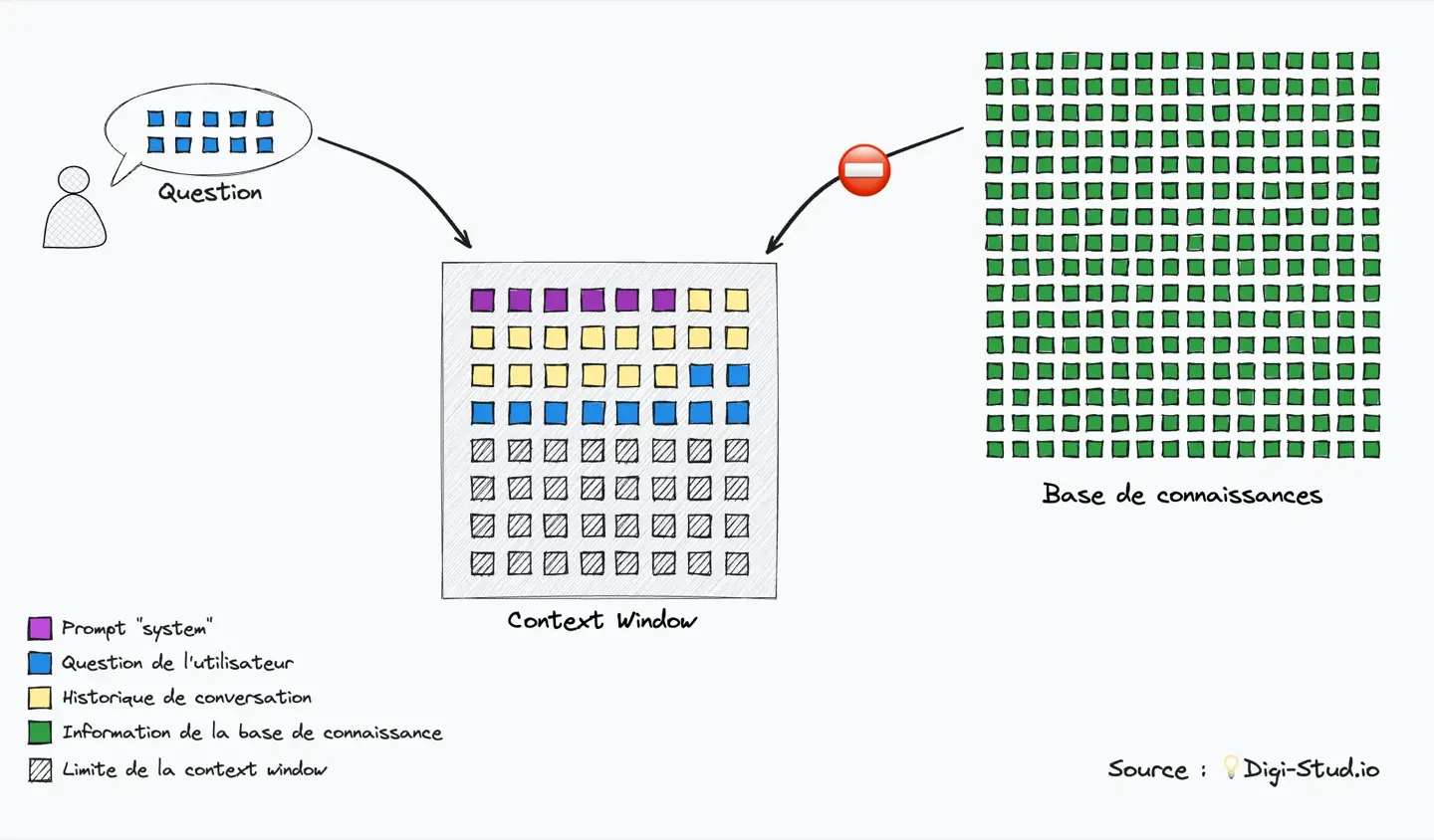
La base de connaissances est généralement plus grande que la context window
Récupération d’information¶
Le principe d’augmenter le savoir d’un modèle de langage en s’appuyant sur une recherche dans des connaissances externes répond au doux nom de Retrieval Augmented Generation (RAG).
Pour réussir à extraire les informations pertinentes dans un large volume de texte, les applications IA utilisent les embeddings : il s’agit de techniques pour vectoriser l’information.
Imaginons une base de connaissances telle qu’une encyclopédie historique par exemple : on pourrait classer l’information par époque pour faciliter la recherche. Avec les embeddings, au lieu d’avoir seulement une dimension, on utilise des algorithmes mathématiques et sémantiques pour classer l’information sur une multitude de dimensions (1536 dimensions dans l’embedding text-embedding-ada-002 d’OpenAI).
Ainsi, lorsqu’une question est posée au chatbot, il calcule l’embedding de la question et le compare aux embeddings des différents morceaux de la base de connaissance externes (ceux-ci sont calculés lors de l’établissement de la base de donnée). On va alors retenir les embeddings les mieux alignés : c’est ce que l’on appelle la recherche par similarité (similarity search) et c’est ce qui permet à l’IA de s’appuyer sur la connaissance externe sans avoir à intégrer l’intégralité de la base dans la context window.
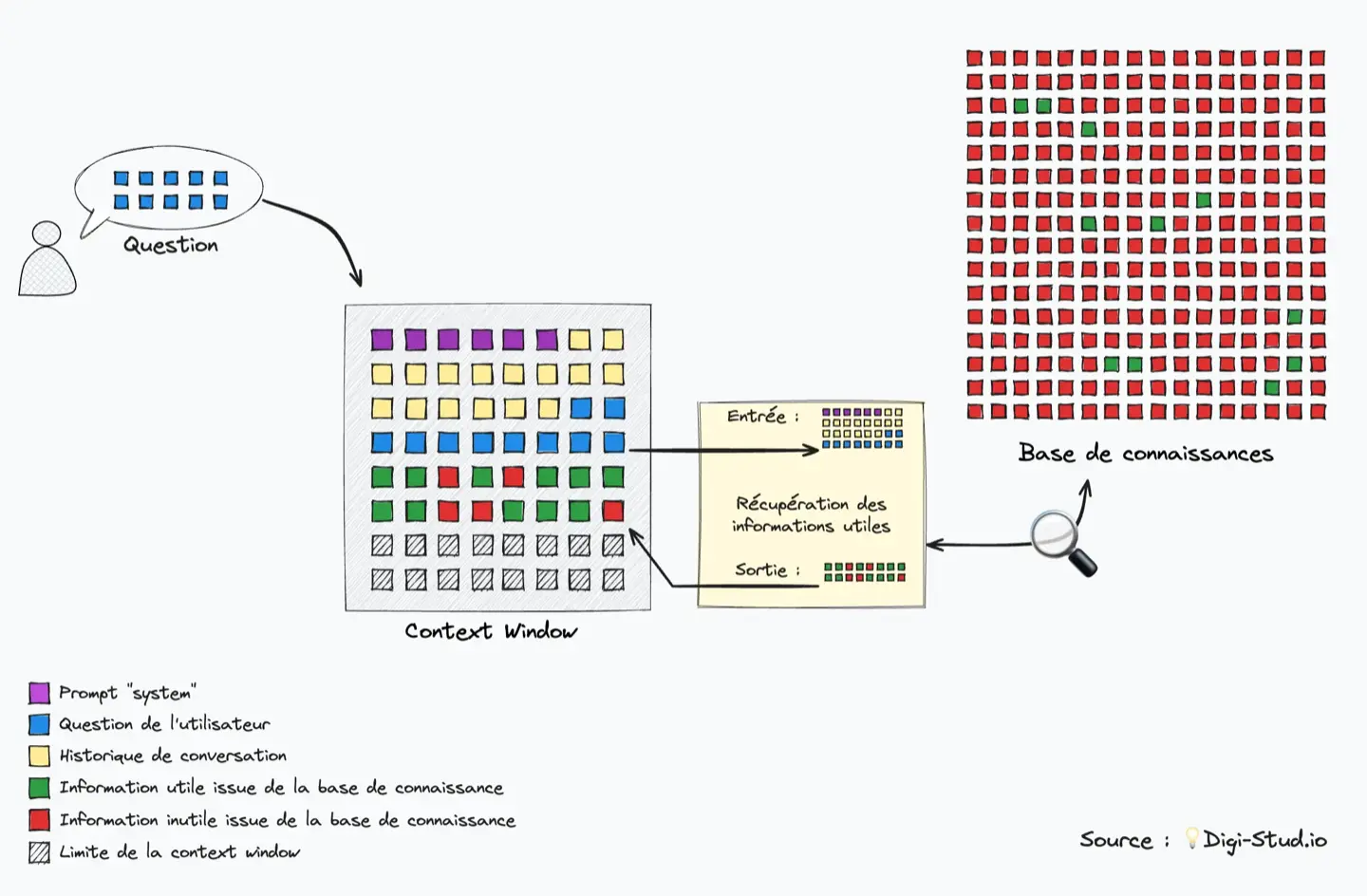
Ces techniques sont aujourd’hui très faciles à mettre en œuvre, notamment grâce aux API d’OpenAI, mais il ne s’agit pas pour autant d’une technique infaillible et il est important d’avoir conscience des limites de cette approche : l’IA n’a pas conscience de la globalité de la base de connaissance et peut donc produire des réponses inexactes ou partielles.
Example
Imaginons une base de connaissance constituée de fiches techniques de différents produits industriels, en grande quantité. Pour chaque produit, la fiche décrit les principaux usages du produit, ainsi que la liste détaillée de ses caractéristiques techniques (résistance à la chaleur par exemple).
- ✅ le chatbot sera en mesure de répondre à la question “propose-moi des produits adaptés à telle problématique“
- ❌ le chatbot produira des réponses décevantes pour la question “quel produit à la plus haute résistance à la chaleur” car il faudrait alors lire la totalité de la donnée donner une réponse.
De nombreux paramètres entrent en compte :
- le choix de l’algorithme d’embedding (générique ou spécialisé)
- la qualité de la donnée
- la structuration de la base de donnée (taille des extraits)
- le traitement de la question de l’utilisateur
- le type d’information et de question
Pour créer une application professionnelle fiable, il est essentiel de maitriser tous ces paramètres pour contrôler au mieux les résultats produits.
Traitement de la donnée en amont¶
Avant de constituer la base de donnée, la première étape consiste à nettoyer la donnée. Dans mon cas, j’avais besoin de construire une base de connaissance à partir de centaines de documents PDF (fiches techniques et brochures). Il s’agit alors d’extraire et de nettoyer le texte, en éliminant si possible les caractères spéciaux. Les tableaux doivent également être extraits et transformés pour une meilleure digestion par les modèles de langage. Et ce n’est pas toujours une mince affaire avec les documents PDF !
Il existe plusieurs librairies permettant d’extraire et de nettoyer le contenu de documents PDF, notamment des modules Python utilisés dans LangChain mais aussi Unstructured qui se spécialise le nettoyage de donnée pour les modèles de langage. Dans mon cas, j’ai choisi d’utiliser l’API d’Adobe qui permet d’extraire un contenu relativement propre.
Une technique qui m’a donné de bons résultats consiste à extraire les tableaux sous forme d’image (avec l’API d’Adobe) puis d’appliquer un premier traitement IA avec GPT-VISION pour transcrire le contenu et la signification du tableau en texte rédigé. Bien sûr, il faut automatiser la tâche pour pouvoir traiter des centaines de documents à la chaîne !

Il faudra également limiter la redondance d’information. Pour rappel, l’objectif est de rechercher dans la base de connaissance pour retourner un nombre limité d’extraits. Si une information est présente plusieurs fois, elle risquerait de prendre la place d’autres extraits potentiellement utiles.
Constitution de la base de donnée¶
Une fois l’information traitée, il faut de découper l’information en morceaux (chunks). Pour chaque morceau l’embedding est calculé et un enregistrement est ajouté à la base de donnée avec le texte original et l’embedding. Des métadonnées peuvent être ajoutées (nom du document, page de l’extrait, etc). Les paramètres de segmentation de l’information devront être choisis en fonction de la nature du contenu, du rôle du chatbot et du type de question attendue :
- Des morceaux de grande taille offriront une compréhension globale alors que des morceaux plus petits permettront de cibler des détails spécifiques.
- Certains contenus peuvent perdre leur substance s’ils sont trop découpés (par exemple des comparaisons de produits).
Techniques de recherche¶
Pour la recherche d’informations, plusieurs techniques peuvent être appliquées :
- Le multi-query consiste utiliser un premier prompt pour obtenir plusieurs reformulations. Plusieurs recherches seront alors effectuées en parallèle et les meilleurs résultats de chaque recherche seront retenus.
- Une autre technique, appelée contextual compression, consiste à utiliser un prompt intermédiaire pour réduire le volume d’informations en ne retenant que les éléments pertinents pour répondre à une question.
Pour construire ces chaînes de traitement, on peut s’appuyer sur le framework LangChain (Python et JavaScript) qui permet d’abstraire ces différents concepts. L’outil d’automatisation n8n propose une implémentation de LangChain en visual coding. LangChain permet également d’abstraire les fournisseurs de services, ce qui permet de tester d’autres IA comme Mistral AI, la licorne française.
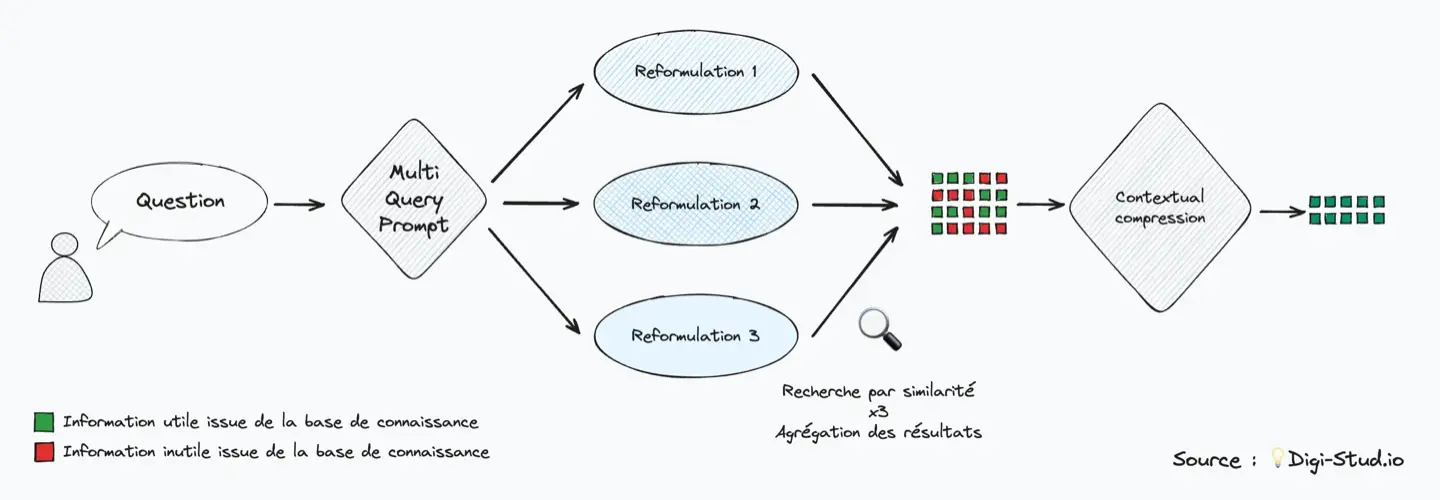
Lors de mes tests, une technique qui s’est avérée efficace est de mener en simultané une recherche par similarité utilisant les embeddings et une recherche traditionnelle de mots clés (les mots clés étant sélectionnés avec prompt adapté).
Observabilité et protocole de test¶
Compte tenu du nombre d’étapes et de paramètres, l’observabilité est un aspect essentiel pour itérer et converger vers un résultat satisfaisant. Des solutions proposant des journaux d’exécution (logs) exhaustifs permettront de suivre les différentes étapes d’une requête (prompts intermédiaires, récupération d’information, réponse, etc.).
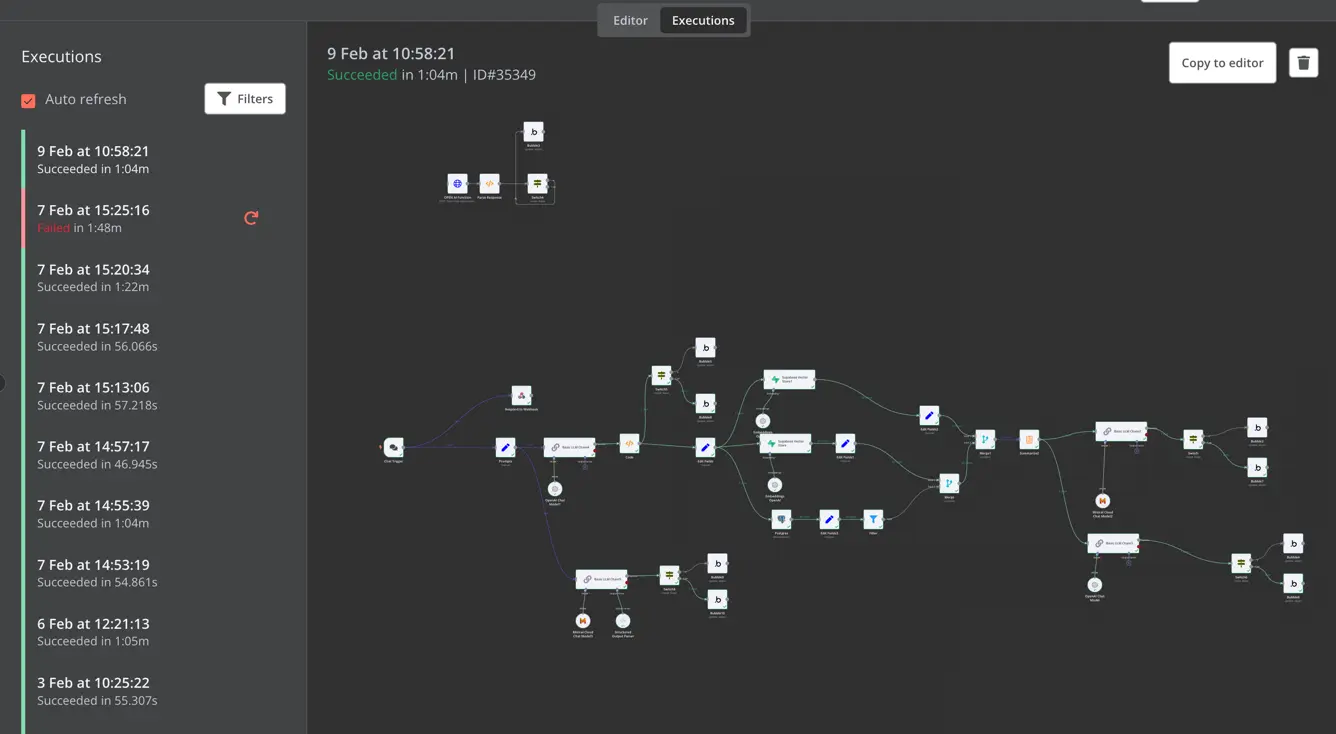
n8n est un outil de visual coding qui offre une implémentation du framework LangChain et un journal d’exécution détaillé
Il est par ailleurs utile de recueillir l’avis des utilisateurs sur les réponses afin de pouvoir revenir sur les réponses insatisfaisantes et de chercher des pistes d’amélioration. Je réfléchis également à mettre en place une évaluation de la réponse a posteriori par un traitement IA (évaluation de la pertinence des extraits récupérés notamment).
Pour finir, la capacité d’automatiser la production de réponses sur un panel de questions de références permettra de générer en masse des variantes du système pour les faire évaluer par les utilisateurs et experts métiers.
À suivre…¶
Ici s’arrête ce premier retour d’expérience. Je continue d’explorer et j’ai encore beaucoup de choses à apprendre. De plus les outils évoluent vite : fin janvier, OpenAI a annoncé la mise sur le marché de nouveaux algorithmes d’embedding plus récents et plus efficaces.
J’espère proposer d’autres articles prochainement pour présenter les outils et les paramétrages que j’aurai pu tester et évaluer.